|
1
|
|
|
2
|
- Joining A to B, assuming A has a better filter than B (almost certainly
true for a correct nested-loops join order):
- Nested Loops: For each A, find matching Bs following the indexed join
key.
- Hash Join: Reach B as if with a single-table query, then line up A-to-B
matches on the hash of the join keys.
|
|
3
|
- Nested-loops join reaches a large fraction of a small joined-to table:
Optimizer tends to prefer a hash join, correctly, but both alternatives
are well-cached and fast.
- Nested loops obviously reach a tiny fraction of a large joined-to table:
Optimizer tends to prefer a nested-loops join, correctly, and this is
much faster than the hash-join alternative.
|
|
4
|
- Nested loops reach a tiny fraction of a large joined-to table, but the
optimizer greatly over-estimates that fraction: Optimizer would prefer a
nested-loops join, if it knew more, and this is much faster than the
hash-join alternative.
- This tends to happen for “exceptions” reports, where two conditions are
almost mutually exclusive, but the optimizer’s assumption of
statistically independent conditions yields the over-estimate.
- As humans, we can and should expect reasonable rowcounts in reports, so
we should often expect this case.
|
|
5
|
- Nested loops reach a large fraction of a large joined-to table:
Optimizer will strongly (and usually correctly) prefer a hash join to a
full table scan, taking into account the benefit of multi-block reads,
and avoiding multiple logical I/Os to the same blocks.
- When the join order is correct, this almost always implies a huge set
of rows being returned by the query.
- Such large return rowsets are very rarely useful for human consumption,
but can reasonably occur in middleware or conversion processes.
|
|
6
|
- Nested loops reach a medium-sized fraction of a large joined-to table:
Optimizer will mildly prefer a hash join to a full table scan, taking
into account the benefit of multi-block reads, and avoiding multiple
logical I/Os to the same blocks.
- In this common case, nested-loops are frequently preferable to the
hash-join choice of the optimizer, largely owing to self-caching in
queries of naturally clustered tables.
|
|
7
|
- Tables that grow the largest track frequent business events, such as
product orders, customer calls, account payments, et cetera.
- The application exists to drive correct business actions and choices,
and these in turn depend on recent events.
- Therefore, most data queried from large tables concerns recent events,
and was recently added to those tables, clustered at the top.
|
|
8
|
- Event-type tables rarely stand alone – they usually join to several
other events-related tables tracking related events and event details.
- Joins to large tables are therefore usually from recent event-type data
in one table to related, recent, event-type data in another table.
|
|
9
|
|
|
10
|
|
|
11
|
- We can reach 30,000 rows or more per second with nested loops to cached
data, a trivial time compared to the magnitude of the output, unless a
bad join order reaches tables in the wrong order! (What application must
produce multiple 30,000-plus-row reports per minute, even in the worst
case?)
- Where nested-loops costs matter, it is because physical I/O time is
high, or the join order is wrong.
|
|
12
|
- If the join key is an ordinary sequence-generated ID, the join-key index
will naturally cluster in the order the rows were created.
- In this case, the query need only cache a few blocks to read thousands
of rows from the recent end of the table – index-block I/O costs are
trivial thanks to self-caching early in the query execution, even if
these blocks are not yet cached.
|
|
13
|
- In the ideal case (which is surprisingly close to the common case!), the
joined-to table is accessed roughly in row-creation order.
- Read-ahead in the disk subsystem effectively converts reads like this
into multi-block reads.
- These two effects lead to physical I/O much like a fractional table scan
of only the top of the heap table (which is likely largely cached,
anyway).
|
|
14
|
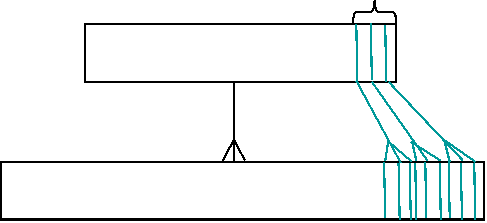
- Two million-row tables, joined one-to-one, matching rows created in the
same order, reading the most-recent 1% of the rows:
|
|
15
|
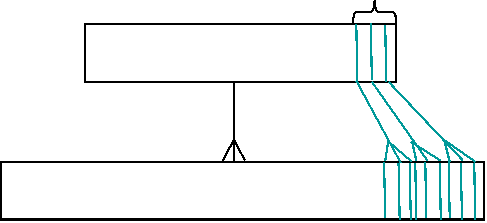
- Two million-row tables, joined one-to-one, matching rows created in the
same order, reading the most-recent 1% of the rows:
|
|
16
|
- Two million-row tables, joined one-to-one, joined-to matching rows
created in scattered order, reading the most-recent 1% of the
driving-table rows:
|
|
17
|
- Two million-row tables, joined one-to-one, joined-to matching rows
created in random order, reading the most-recent 1% of the driving-table
rows:
|
|
18
|
|
|
19
|
- Cost function predicts relative runtimes well in non-co-clustered case!
- Co-clustered case is more important, though, and greatly favors nested
loops!
|
|
20
|
- The join method to small tables matters little, but tends to slightly
favor hash joins for queries returning substantial rowcounts.
- Hash joins to large tables can win in rare cases where sensible queries
return (or summarize) very high rowcounts.
|
|
21
|
- Hash joins to large tables can win in cases where the join order is
wrong, or where join-key indexes are missing or disabled through
join-key type conversions or other index-disabling functions.
- (In the above case, the better solution is to enable the optimum
nested-loops plan!)
|
|
22
|
- Nested loops almost always win when the CBO prefers them.
- Hint-forced nested loops usually win when the CBO underestimates the
combined selectivity of multiple filters (when mutually-exclusive
conditions violate the assumption of statistically independent
conditions).
|
|
23
|
- Hint-Forced nested loops in the best join order usually win in the
common case of joins from recent rows to related recent rows (joins
between naturally co-clustered tables).
- Hash joins to large full table scans are rarely better than the best
nested-loops plan.
|
|
24
|
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}