Quarterly SingingSQL Newsletter #4
Introduction
If you wish to unsubscribe at any time, just drop me a line at dantow@singingsql.com. I’ll likely eventually get around to setting up a proper email group, through some third party, so that eventually people can subscribe and unsubscribe without communicating with me, but this is simplest for a start, I think.
I’m taking a lowest-common-denominator approach to the format of this newsletter, sending it as a straight-ASCII note so anyone at all can access it securely, but if you’d rather read something more formatted, go to OnlineNewsletter04. (I recommend this particularly for this edition, since it has complex figures that don’t translate well to simple text.) I’ll also have links scattered throughout for supplementary materials.
Although this material is copyrighted, feel free to forward this newsletter, as is, to any friends who you think might be interested.
If you have any comments, ideas for future newsletter content, or suggestions, feel free to drop me a line, at dantow@singingsql.com – I’m always happy to hear from you!
SingingSQL News of Public Events
Old Old News
To see a cumulative listing of all news, including old news from past newsletters, see all news.
Old news
- I
presented my Top-Down SQL Tuning course based on my book in
New news
- I will present my new seminar, Getting SQL Performance Right the First Try (Most of the Time) at the coming HOTSOS conference in Dallas sometime during the March 4-8 schedule.
- I plan to expand my class offerings outside of the San Francisco Bay Area, but I’d like to do this mainly through partners who already know prospective students in their area, likely partners who receive this newsletter. If you think you can find 6 or more paying students in your area, and you’d be interested in a chance to share in the profit from the class, drop me a line, and we can work out a deal for a class in your area. (If you work for a company, and your company wants a class just for its own people, I already have an offering for classes presented on demand for company-internal audiences.)
- I’ve had a few people ask about coming class offerings, and it occurred to me that I don’t have a good way to announce them if they come up suddenly, because I want to keep my promise that this newsletter only comes just four times a year. Therefore, I’m starting a new list for anyone interested in announcements of classes and other offerings (such as presentations to local OAUGs) that might come up without enough warning to make it into this newsletter. If you are interested (and there is certainly no commitment in this, on your part) just drop me a line at dantow@singingsql.com, and I’ll add you to this new list. Please be sure to include your location and some range of area within which you’d consider attending something if I happened by. The area can be as broad as a continent or as narrow as a town – “Let me know if anything comes up in Asia.” to “Let me know if you have a class coming to Darwin, Australia.” Even if you’re off the beaten path, we might get lucky. I won’t send notes for this second list except to the people in the area where I’m offering something, and I doubt you’ll see more than a note or two from this new list per year, even if your area is broad.
Links
Old Links
To see a cumulative listing of all links, including links already listed in past newsletters, see all links.
New Links
I have no new publications this quarter apart from this newsletter.
Featured Article
Extending the Diagram Method for a Special Case
During some recent work at a client, I found a case where the diagramming method I documented in SQL Tuning needed several extensions, so I’d like to offer them in case you find them occasionally useful, as well. The problem was a 9-way join returning 38,000 rows in about 2.2 hours. This discussion will include several fairly detailed query diagrams that won’t look very good in the pure-text version I’m emailing, so I highly recommend that you go to the link OnlineNewsletter04 for prettier, easier-to-read diagrams, if you possibly can. Applying the diagramming method just as I described it in the book, we’d find the diagram:
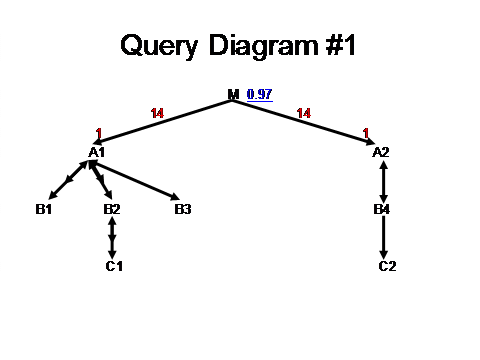
We’re already left with a shortcoming in this diagram, though, because the actual query has a complex set of OR’d-together conditions on A1, B1, B2, and C1. The query cannot discard rows based on these conditions until all four of these tables have been reached, however, so the filter ratio for this complex set of conditions really belongs to all four of these tables, combined. Another complexity is that the join from M to A1 really looks like
…
Here, M uses just a single foreign key to point to A1, but we can make the join to A1 unique only by including the condition A1.PKey2_ID=:Constant, which specifies the value for the second half of A1’s two-part primary key. It’s standard practice to treat such a literal condition on a part of a primary key as simply being part of the join, rather than as a filter condition (on A1, in this case), but we’ll need to come back to this extra bit of complexity, later. For now, though, I’ll just treat this as if “A1” simply refers to the subtable of the real table having the correct value for PKey2_ID.
Returning to that pesky multi-table filter, though, here’s a simple way to diagram such a filter that only can be evaluated once all four tables A1, B1, B2, and C1 are reached:
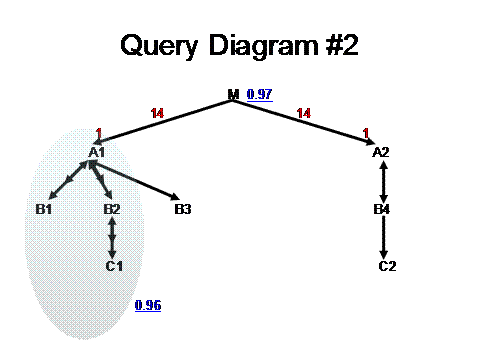
Here, the “0.96” next to the elliptical cloud covering A1, B1, B2, and C1 signifies that the OR’d-together conditions on those tables will be true for 96% of the rows we reach if we join A1 (really, the subtable of A1 having A1.PKey2_ID=:Constant) to B1, then to B2, then to C1, a rowcount that is 96% of the rowcount of the subtable of A1 having A1.PKey2_ID=:Constant. Now, if we just look at this diagram and forget everything else we might know about the problem, and apply the method as described in the book, we’d conclude the following:
- The best (well, tied for best) nested-loops join order would be {M, A1, B1, B2, C1, B3, A2, B4, C2}.
- We shouldn’t probably use nested-loops, since we don’t have a single filter that throws out a decent number of rows! Instead, the best plan ought to be a series of hash joins of full table scans, starting with the smaller tables (Yuck!).
- The final rowcount, which is reduced by just two poor filters, should be 0.97*0.96*RowcountOfM. Since the rowcount of table M is 14-million rows(!), this formula predicts a query result of just over 13-million rows! This is manifestly higher than the observed rowcount of 38-thousand rows, by a factor of 343! Clearly, something unusual is going on!
The first thing we might suspect is that perhaps one or more of the joins to B3, A2, B4, or C2 actually discards rows, that perhaps one of those joins has a master join ratio of something like 1/343. As it happens, though, the master join ratios for these joins are all precisely 1, so that’s not where we are losing rows. We can even remove those joins, leaving just M, A1, B1, B2, and C1, and we still get the 38-thousand-row result. The next thing to suspect is anti-correlation. The usual assumption (the assumption that would lead us to expect a 13-million-row result) is that each filter is statistically independent, discarding the same fraction of rows from either the table or the set of joins up to the point where that filter is reached, with any join order. (Like my method, optimizers implicitly make this assumption, and it would be hard to do better with any reasonable set of statistics an optimizer could work from.) With statistically independent filters, we’d expect a join of two tables each having filter ratios of 0.5 to return 25% (0.5*0.5) of the rows from the larger table. Two perfectly anti-correlated filters of 0.5 could result in no rows at all, if the half of the rows passing the first filter joined precisely to the half of the rows that would not pass the second filter. Here, however, anti-correlation of the filters is not sufficient to explain the result – even if all the discarded rows from one filter would have joined to rows that passed the second filter, leaving the minimum number of rows remaining to pass, we ought to keep 93% of the rows (1-(1-0.96)-(1-0.97)).
In fact, the two filters are statistically independent! The correlation is more subtle! Note that the statistics (the master and detail join ratios, that is) for the join from M to A1 are for the unfiltered tables. As it happens, although on average a row of A1 (having A1.PKey2_ID=:Constant)) joins to 14 rows of M, most rows (94%) of A1 fail to join to M at all! (This is quite uncommon with one-to-many relationships, which usually find at least one detail for every master row. For example, an order makes no sense without at least one order line.) Furthermore, almost all the rows of A1 that do join to M do not join to rows of B1, B2, and C1 that will pass the multi-table filter, so the multi-table filter and the join from A1 to M are highly anti-correlated! So, the join from A1 to M is what takes the expected result set of 13-million rows down to a result of just 38-thousand rows. Well, we could just join these two tables early, but then we’re stuck with an intermediate result of almost 14-million rows until we can join all of the tables B1, B2, and C1 (all of which are roughly million-row tables and are poorly cached), before we finally pick up that anti-correlated multi-table filter, and those are going to be some very expensive joins! Alternatively, we could get close to a million rows from A1, B1, B2, and C1, pick up the multi-table filter, and do the join to M as the fifth table in the join order, trimming the result set to 38-thousand rows before joining to B3, A2, B4, and C2, but those first four joins are going to be awfully expensive (though better than the initial plan).
The trick is to recognize that we don’t have to do the join from A1 to M to pick up the implicit filter buried in that join! Instead, we can just do a semi-join, early in the plan, in the form of an EXISTS condition. Any one-to-many inner join implies such an EXISTS condition (“There exists at least one detail for each of these masters.”), but only very rarely is this a condition that would discard many rows or help performance. Of course, this EXISTS condition is logically redundant, but it is nevertheless very useful for performance! As one final trick, it turns out that we can even pick up this very useful exists condition without going to the table A1, first, because there is an index, already, on A1(PKey2_ID, PKey1_ID), which is all we need to perform the EXISTS check before we reach the table A1 with a ROWID join from the index (which we could replace with a join to the primary key, with slight loss of efficiency on a database that doesn’t support ROWID joins):
The new query will read
SELECT /*+ push_subq ORDERED USE_NL(A1Tab B1
B2 C1 B3 M A2 B4 C2 */
<select list that does not reference A1Ind>
FROM A1 A1Ind, A1, B1,
B2, C1, B3, M, A2, B4, C2
WHERE <same as
before>
WHERE MS.FKey_ID=A1Ind.PKey1_ID)
We need just one final innovation to wrap up the solution: We don’t really care how selective a filter is overall – what we really care about is how selective it is at the point in the join order that we pick up the filter! Normally, these are the same (when filters are statistically independent, that is), but this case is an exception. The same goes for join ratios – the ratio that matters is the ratio that applies at the point in the join order where we perform that join. Unfortunately, this creates a bit of a chicken-and-egg problem – how do we find the join order without knowing the filter ratios, and how do we find the filter ratios (which depend on the join order, when they are statistically correlated or anti-correlated), before we know the join order? Well, this is a problem, but fortunately we’re unlikely to find enough statistically correlated or anti-correlated filters for this to create real problems in practice. In practice, we can just try it both ways (usually not more than 2 likely possibilities) and see which one comes out with a faster query. In this case, replacing the independent filter ratios with the correct ratios in context, the diagram for the best join order ({A1Ind (index-only range scan), MS (semi-join), A1 (ROWID join), B1, B2, C1, B3, M, A2, B4, C2}) is (and note that the condition of A1Ind.PKey2_ID=:Constant is now being treated like a filter, getting 1 million index entries out of the 50-million-entry total):
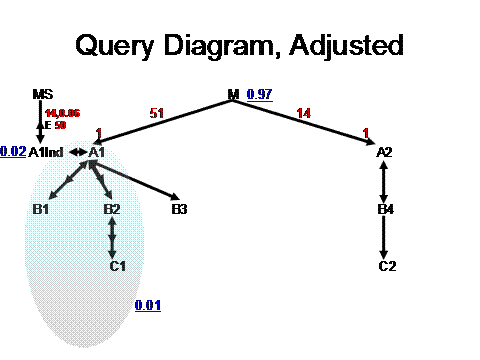
Now, if we apply the methods from the book to this diagram, the join order and plan are clear – reach 1-million index entries in A1Ind, follow a nested-loops semi join to MS (to check the EXISTS condition, then reach the table A1 with the remaining 60-thousand ROWIDs from the index (that survive the EXISTS check), then nested loops to B1, B2, and C1, finally picking up the excellent anti-correlated multi-table filter, reducing the rowcount to 600, (closer to 770, really, but I’m rounding), then join 770 rows to B3, then do 770 one-to-many joins (which will all succeed, since these are the rows that pass the EXISTS condition!) to reach 39-thousand rows in M, and discard a thousand rows that fail the filter on M, finally joining 38-thousand rows to A2, B4, and C2.
The resulting query ran in 4.4 minutes – a 30-fold speed-up, and very fast for a query reaching this many rows and joining so many large tables!
Research Problems
Old Research Problems
To see a cumulative listing of all research problems (the one below, and the earlier ones from the earlier newsletters), see all research problems. There has been no solution submitted yet for the earlier-published research problems.
New problem: Opportunistic, Iterative Tuning
Here’s an extension of last quarter’s research problem, which was to consider cases when it might be worthwhile to halt and retune a query in the middle of its execution. Even if it never changed plans “midstream,” the optimizer could still gather information relevant to whether it should choose a new plan the next time that SQL executes. What sort of data should the database gather during execution pertaining to finding a better plan for a later execution. When should it bother? What sort of data should the database gather offline? When should it bother? How and when should it use that data to find a better plan for a later execution? (I have a number of ideas regarding possible answers, but I’d first like to open up the discussion.) Does any database besides Oracle10g (which has some capability along these lines) do something like this? Propose a good algorithm for a database that would. How well can we apply the answers to these questions to finding more effective methods to choose which SQL to tune manually and to improving the actual process of manual tuning?
©2006 Dan Tow, All rights reserved